Unearthing The Digital Past: A Deep Dive Into 4chan Archives
The digital landscape is vast and ever-changing, but within its depths lie hidden repositories of information, conversations, and cultural phenomena. One such intriguing realm is that of 4chan archives. These digital time capsules preserve snippets of a platform known for its ephemeral nature, offering a unique window into internet history, subcultures, and the evolution of online discourse.
4chan, launched in October 2003 by Christopher "moot" Poole, quickly established itself as a controversial yet influential English-language imageboard, drawing inspiration from Japanese sites like Futaba Channel. With its emphasis on anonymity and rapid-fire discussions across dozens of specialized boards, much of its content vanishes quickly. This transient nature makes the concept of 4chan archives not just interesting, but essential for understanding its profound and often perplexing impact on contemporary online culture.
Table of Contents
- What Are 4chan Archives and Why Do They Matter?
- The Ephemeral Nature of 4chan and the Drive to Archive
- Early Attempts and Community-Driven 4chan Archiving
- The Diverse Content Within 4chan Archives
- Controversies, Hacks, and Their Impact on 4chan Archives
- The Future of 4chan Archiving
What Are 4chan Archives and Why Do They Matter?
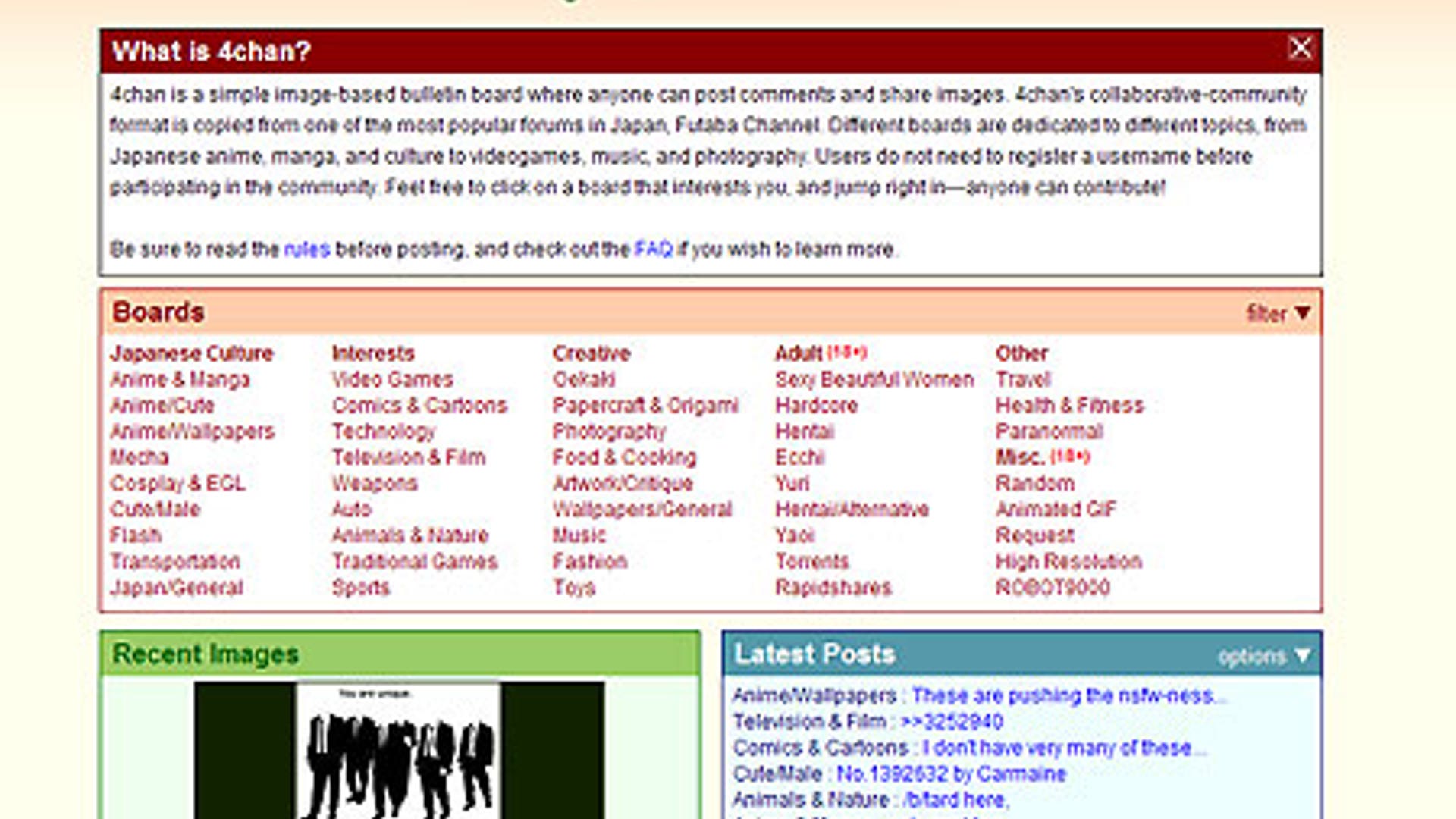
At its core, 4chan is an English-language website based on the Japanese Futaba Channel, where people can post and discuss pictures and other images. These types of sites are called imageboards. The majority of posting on 4chan takes place on these imageboards, on which users have the ability to share images and create threaded discussions. As of August 2022, the site's homepage listed 75 imageboards and one flash animation board. Most boards have their own set of rules and are dedicated to a specific topic, ranging from video games and anime to politics and technology.
Given this dynamic and often chaotic environment, the concept of 4chan archives emerges as a critical endeavor. Simply put, 4chan archives are collections of saved threads, images, and other content from the 4chan website. Unlike traditional forums where content persists indefinitely, 4chan threads are designed to be ephemeral. They quickly scroll off the board as new posts are made, eventually becoming inaccessible (a "404" error). This transient nature means that without dedicated archiving efforts, vast swathes of internet history, cultural phenomena, and pivotal discussions would be lost forever.
Why do these archives matter? For several reasons. Firstly, they serve as a historical record. Many internet memes, subcultures, and even real-world events have roots or significant discussions on 4chan. Preserving these threads allows researchers, historians, and curious individuals to trace the origins and evolution of these phenomena. Secondly, they offer insights into online communities and human behavior. 4chan's unique blend of anonymity and diverse topics makes it a fascinating case study for understanding collective intelligence, social dynamics, and the darker aspects of online interaction. Finally, for those who participated in specific threads or witnessed significant events unfold on the site, these archives can be a form of digital nostalgia, a way to revisit moments that shaped their online experience.
The Ephemeral Nature of 4chan and the Drive to Archive
The very design of 4chan fosters ephemerality. Threads are not meant to last; they are constantly pushed down by new content, eventually disappearing from the live boards. This rapid turnover is part of what gives 4chan its unique energy and appeal for many users – a sense of immediacy and a lack of long-term accountability. However, this also means that valuable or historically significant content can vanish in a matter of hours or days, making the drive to create 4chan archives a necessity for anyone interested in preserving this digital legacy.
- Great Harvest
- Israel Iran Border
- Iran Noticias Espa%C3%A3ol
- Alamo Drafthouse Cinema Brooklyn
- Weather Iran Kerman
The challenge of preserving 4chan content is multifaceted. Unlike platforms that are indexed by search engines or designed for permanent storage, 4chan's content is largely unindexed and self-deleting. This inherent transience means that manual saving or automated scripting is the only way to capture moments before they are lost. The community itself, recognizing this impermanence, has often taken it upon themselves to save threads they deem important, funny, or historically significant. This grassroots effort highlights the value placed on these digital artifacts, even by those who contribute to their fleeting existence.
Early Attempts and Community-Driven 4chan Archiving
The history of 4chan archiving is as old as the site's significant impact. Early efforts were largely community-driven, with individuals and small groups creating their own repositories. Webpages from 4chan, saved between late 2009 and early 2012, represent some of the earliest systematic attempts. Many of these are from chanarchive, /b/ (the infamous "random" board), or other boards not archived by the fuuka archivers, making them extremely valuable. These early archives are often the only remaining records of specific threads, especially those from boards like /b/ which are known for their rapid content turnover and often controversial or bizarre discussions.
These initial archiving projects, though often rudimentary by today's standards, laid the groundwork for more sophisticated systems. They demonstrated the sheer volume of content that needed to be preserved and the technical challenges involved in doing so. The fact that many of these early archives are still sought after today underscores their importance as primary sources for understanding the early days of 4chan and the internet culture it helped shape.
Tools and Technologies for 4chan Archiving
The drive to preserve 4chan content has led to the development of various specialized tools and scripts. These range from simple user-made scripts to more complex middleware solutions, all designed to overcome the site's ephemeral nature. A common approach involves using the site's API (Application Programming Interface) to programmatically pull data. For instance, there are sets of scripts specifically designed to archive threads from 4chan, using this API. Some users even plan on using these archives to "feed some computer brain projects," hinting at the potential for AI and machine learning to analyze the vast datasets of archived 4chan content.
One notable example of an advanced archiving tool is Ayase. Ayase is a 4chan archiver API middleware and HTML frontend based on Python, developed as a replacement for older systems like FoolFuuka. It supports both Asagi and Ayase SQL schema compatible scrapers, indicating a robust and adaptable architecture for capturing and storing thread data. Beyond comprehensive solutions, more specialized scripts exist, such as a "4chan archived images downloader," which allows users to download all images from an archived thread. These tools often offer features like saving media content from a provided 4chan thread URL, logging thread URLs, and archiving all images, thumbnails, JSON data, and converted HTML of a 4chan thread. The script will continue until the thread 404s or the connection is lost, ensuring maximum capture before content disappears.
The Diverse Content Within 4chan Archives
The content found within 4chan archives is as varied as the discussions on the live site itself. It's not merely text; archives typically include images, thumbnails, JSON data (which contains structured information about posts), and converted HTML of threads. This comprehensive capture ensures that the context, visual elements, and underlying data of a discussion are preserved, offering a richer historical record than text alone.
Specific examples highlight this diversity. There are archives of "4chan banner backups," with some files even found on platforms like Mediafire, showcasing how different types of site-related content are deemed worthy of preservation. More substantial collections include the "4chan thread PDF collection 2019 by anon," which compiles saved threads from various boards like /lit/ (literature), /pol/ (politically incorrect), and /g/ (technology). This particular collection, published in 2019, is open-source and provides a significant snapshot of discussions from those boards. Another example is a "PDF archive of a 2012 /b/ thread on 4chan," which was originally uploaded onto 4chan itself, demonstrating an early form of self-archiving by the community.
These examples illustrate that 4chan archives are not monolithic. They capture the full spectrum of 4chan's content, from the mundane to the infamous, reflecting the site's wide variety of topics, from video games to current events. They are invaluable for understanding the specific cultural moments and discussions that unfolded on this unique platform.
Navigating and Maintaining 4chan Archives
Creating 4chan archives is one challenge, but navigating and maintaining them presents another. Over time, links can become "dead," making it difficult to access the archived content. This issue is not unique to 4chan but is particularly pronounced given the site's volatile nature and the often ad-hoc methods of early archiving. To combat this, projects exist that contain functions to automatically update dead 4chan and 4chan archive links with live ones. These projects often utilize regular expressions to match 4chan and 4chan archive sites with their respective boards, ensuring that users can still find the content they're looking for even if the original link has changed or broken.
The ongoing maintenance of these archives is crucial for their long-term utility. It requires continuous effort to verify links, ensure data integrity, and adapt to changes in 4chan's structure or archiving technologies. Without such dedication, even the most comprehensive archives could slowly degrade into unusable collections of broken links, undermining the very purpose of preservation.
Controversies, Hacks, and Their Impact on 4chan Archives
4chan is undoubtedly one of the most controversial forums on the web. Entirely anonymous, it has been at the origin of a considerable number of excesses and controversies. This controversial nature, coupled with its emphasis on anonymity (a direct heritage from Japanese sites like 2channel and Futaba Channel), means that its archives often contain content that is provocative, offensive, or even illegal. For instance, the site gained notoriety when hackers deposited nude celebrity photos on the site, highlighting its role as a platform for disseminating illicit material.
Beyond content controversies, 4chan has also been a frequent target of cyberattacks, which have significantly impacted its stability and, by extension, the integrity and accessibility of its archives. There have been instances where 4chan's website either wouldn't load or showed error messages for a large number of visitors, leading to widespread speculation about possible hacks. Major cyberattacks have left its servers offline for more than 10 days, with some incidents so severe that hackers leaked 4chan’s source code, along with the accounts of its anonymous volunteer moderators. It's strange to look back at 4chan, apparently wiped off the internet entirely by hackers from a rival message board—and seemingly restored a week and a half later. The infamous imageboard, 4chan, has been back online after several weeks of downtime following an extreme hack that saw its source code leaked, alongside personal details for its moderators.
These security breaches and periods of downtime not only disrupt the live site but also pose significant challenges for archiving efforts. Data could be lost, corrupted, or become inaccessible. Furthermore, the leakage of source code or moderator details could potentially compromise the very tools and methods used for archiving, raising questions about the security and trustworthiness of the archives themselves.
The YMYL and E-E-A-T Considerations for Archiving Controversial Content
The controversial nature of much of 4chan's content brings into sharp focus the principles of YMYL (Your Money or Your Life) and E-E-A-T (Expertise, Authoritativeness, Trustworthiness) when discussing 4chan archives. YMYL content refers to topics that could impact a person's health, financial stability, or safety. While 4chan is not primarily a YMYL site, discussions on boards like /pol/ (politics) or /b/ (random) can stray into areas like misinformation, hate speech, or even incitement, which have real-world implications. Archivists and researchers must approach such content with extreme caution and ethical responsibility.
When analyzing or referencing 4chan archives, adherence to E-E-A-T principles becomes paramount. Expertise requires a deep understanding of 4chan's unique culture, slang, and context to accurately interpret archived content. Without this, misinterpretations can easily occur. Authoritativeness means ensuring that the archived material is genuine and has not been tampered with, especially in light of past hacks and data leaks. Trustworthiness involves transparently acknowledging the source of the archives, any known limitations or gaps, and the potentially problematic nature of some of the content. For historians and social scientists, these archives are invaluable for studying the darker undercurrents of internet culture, the spread of misinformation, and the origins of online radicalization. However, presenting such findings requires a rigorous academic approach that prioritizes ethical considerations and responsible dissemination of information, ensuring that the act of archiving does not inadvertently amplify harmful content but rather provides context for understanding it.
The Future of 4chan Archiving
The landscape of 4chan archiving is constantly evolving, mirroring the dynamic nature of the internet itself. As 4chan continues to operate and new content is generated, the need for robust and efficient archiving methods remains. The development of more sophisticated tools, capable of handling vast amounts of data and adapting to changes in 4chan's API or site structure, will be crucial. The mention of using archives to "feed some computer brain projects" suggests a future where artificial intelligence and machine learning could play a significant role, not just in capturing data but also in analyzing, categorizing, and making sense of the immense volume of archived content. This could unlock new avenues for research into online behavior, linguistic patterns, and the spread of ideas.
However, the future of 4chan archiving also involves ongoing ethical debates. What should be archived? How should controversial or harmful content be handled? How can archives be made accessible for legitimate research while preventing their misuse? These questions will continue to shape the direction of archiving efforts, pushing for a balance between comprehensive preservation and responsible stewardship of digital history.
Wikipedia's Role in Documenting 4chan and its Archives
Wikipedia, as a vast repository of human knowledge, plays an interesting meta-role in documenting 4chan and its archives. While Wikipedia itself is not an archive of 4chan content, it serves as a crucial reference point for understanding the site's history, impact, and controversies. The "Talk pages" on Wikipedia, where people discuss how to make content the best it can be, often include discussions about how to improve the "4chan/archive" page, reflecting the community's effort to accurately represent the site's archiving landscape.
The existence of a "Category: 4chan" on Wikipedia, listing 20 pages dedicated to various aspects of the site (though this list may not reflect recent changes), underscores the academic and cultural significance attributed to 4chan. These Wikipedia entries often cite archived 4chan content as sources, demonstrating how the preservation efforts of individuals and groups contribute to a broader understanding of internet history. This symbiotic relationship highlights the importance of both the raw archives and the interpretive, contextualizing work done by platforms like Wikipedia in making sense of a complex and often opaque corner of the internet.
Conclusion
The world of 4chan archives is a fascinating, complex, and often controversial domain within digital preservation. From its origins as an ephemeral imageboard in 2003, 4chan has generated an immense volume of content, much of which would be lost without dedicated archiving efforts. These archives, ranging from early community-driven projects like Chanarchive to sophisticated modern tools like Ayase, capture not just text but also images, JSON data, and full HTML, providing an invaluable historical record of internet culture, memes, and online discourse.
However, the journey of preserving 4chan content is fraught with challenges, including the site's inherent transience, the need for continuous link maintenance, and the ethical dilemmas posed by its often controversial and explicit content. Past cyberattacks have further complicated these efforts, raising questions about data integrity and accessibility. Despite these hurdles, the ongoing drive to create and maintain 4chan archives underscores their significance as primary sources for researchers, historians, and anyone seeking to understand the raw, unfiltered evolution of online communities. They serve as a stark reminder that even the most fleeting digital interactions can hold profound cultural and historical weight.
- Nuclear Agreement With Iran
- Recent Sanctions Against Iran
- Iran Leader Khamenei
- What Continent Is Iran In
- Iran Sudan

4chan – PC Tech Magazine
4Chan's Greatest Hits | Fox News
Was ist eigentlich 4chan? - Computer & Medien - Badische Zeitung
